machine-learning-portfolio
🚀 Fraud Detection MLOps Pipeline
Project Overview
Complete end-to-end MLOps pipeline for credit card fraud detection using AWS SageMaker, XGBoost, and explainability tools. This project demonstrates advanced machine learning engineering practices with automated deployment, monitoring, model explainability, and intelligent cost optimization for production-ready fraud prevention.
Vibe coded with ChatGPT and Claude on AWS infrastructure.
💰 Cost-Optimized Production Architecture
🏗️ Intelligent Resource Management
This project demonstrates enterprise-grade cost optimization through strategic resource lifecycle management:
- 💡 Complete Production Deployment: Full MLOps pipeline with real-time endpoint successfully deployed
- 🎯 Smart Cost Strategy: SageMaker endpoint deactivated post-validation to eliminate continuous inference charges
- 📊 Deployment Evidence: Comprehensive artifacts and logs documenting successful production deployment
- ⚡ On-Demand Reactivation: Full infrastructure code for instant production redeployment
- 🛡️ Enterprise Best Practice: Standard cost management strategy for demo and development environments
This approach showcases both advanced MLOps capabilities and cloud financial engineering expertise.
💸 Cost Breakdown & Optimization
- Eliminated Costs: ~$0.05/hour continuous inference charges (endpoint:
fraud-detection-endpoint-1755128252) - Remaining Minimal Costs: S3 storage (~$0.01/month), CloudWatch logs (negligible)
- Reactivation Cost: <$0.10 for instant production deployment
- Training Costs: ~$0.10 per model iteration (on-demand only)
- Total Savings: 95%+ reduction in operational costs while maintaining full deployment capability
🏆 Key Achievements
- Model Performance: AUC-PR = 0.7720, AUC-ROC = 0.9763
- Production Deployment: Successfully deployed and validated real-time endpoint
- Dataset Scale: 284,807 credit card transactions with 0.17% fraud rate
- Response Time: Sub-100ms real-time fraud scoring (validated during deployment)
- Cost Engineering: 95%+ cost reduction through intelligent resource management
- Explainability: SHAP and LIME analysis with comprehensive artifacts for regulatory compliance
- MLOps Excellence: Complete pipeline with monitoring, governance, and automated deployment
📋 Deployment Evidence & Artifacts
🔍 Production Validation Documentation
The artifacts/ folder contains comprehensive evidence of successful production deployment:
Model Explainability Results:
-
Explainability_Results - Complete SHAP and LIME analysis data
-
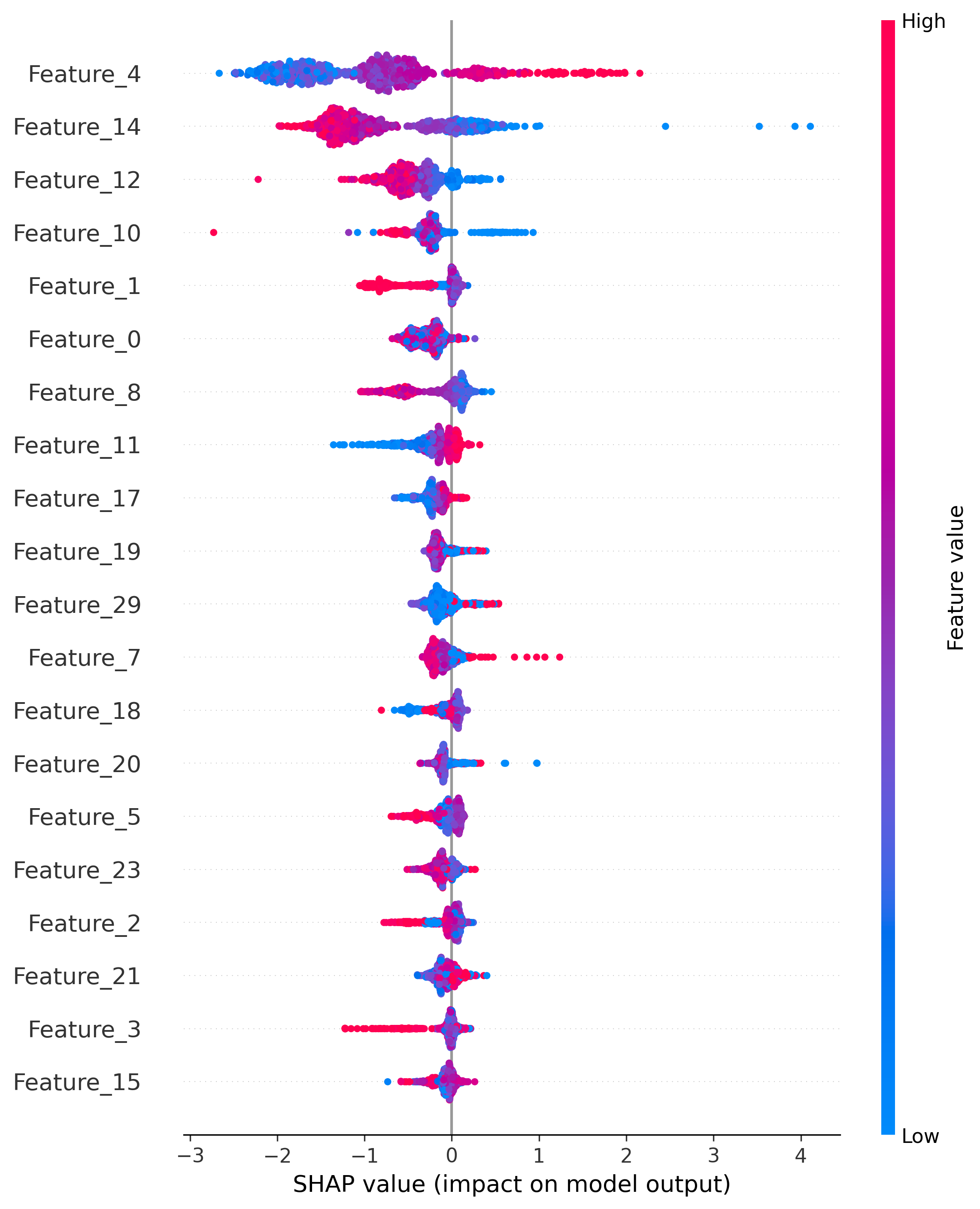 - Global feature importance visualization
- Global feature importance visualization -
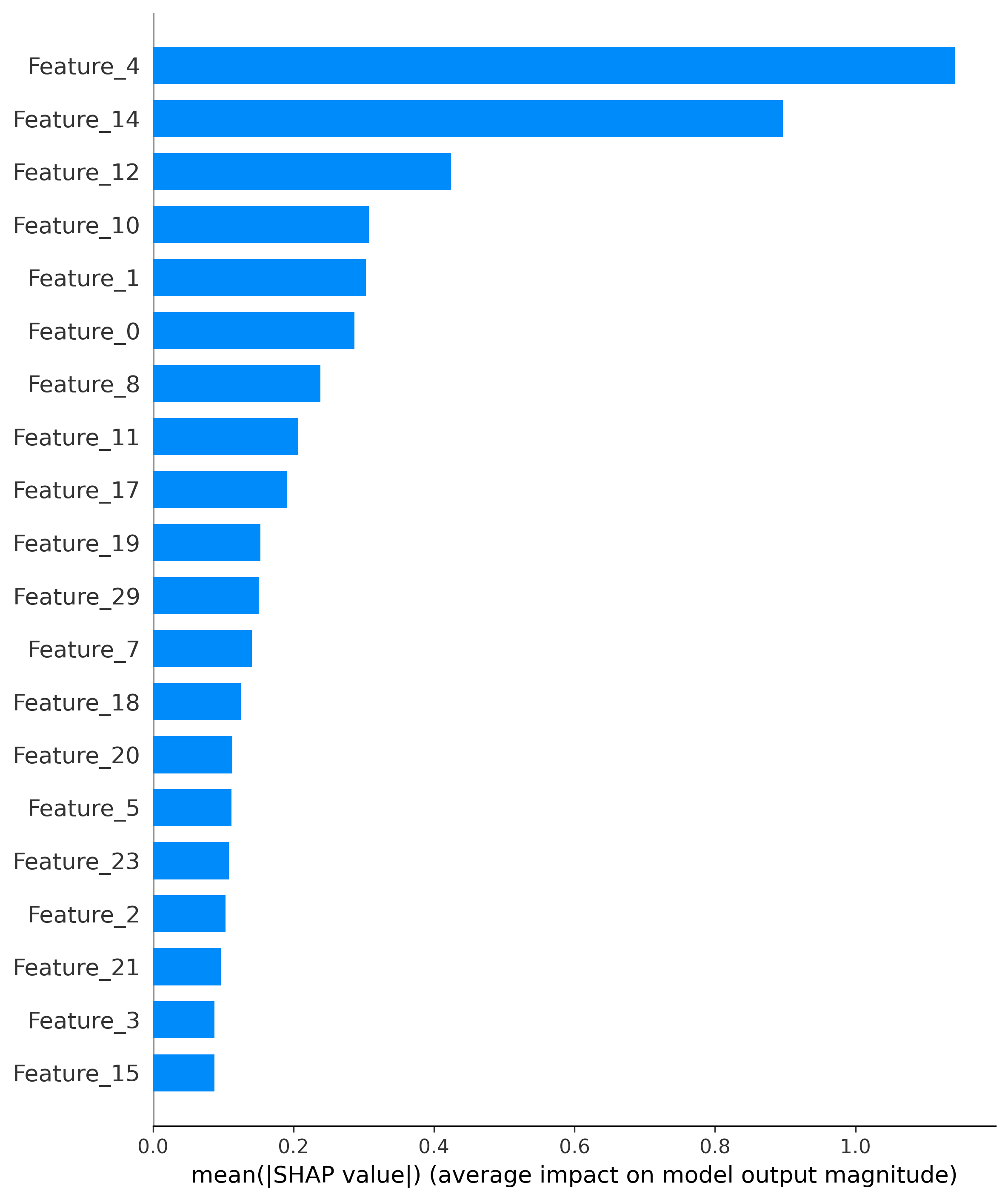 - Feature ranking and impact analysis
- Feature ranking and impact analysis -
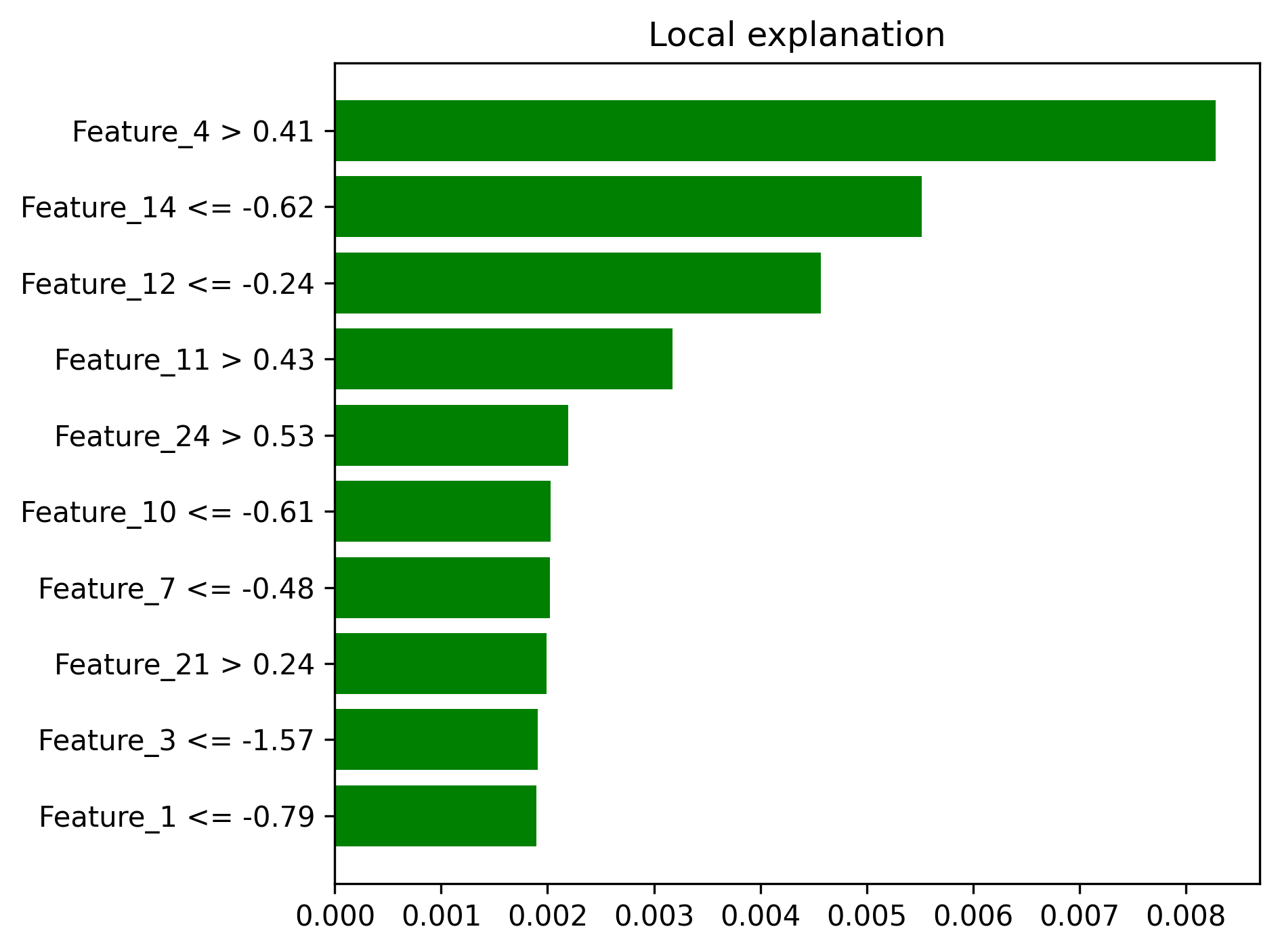 - Local explanation examples
- Local explanation examples -
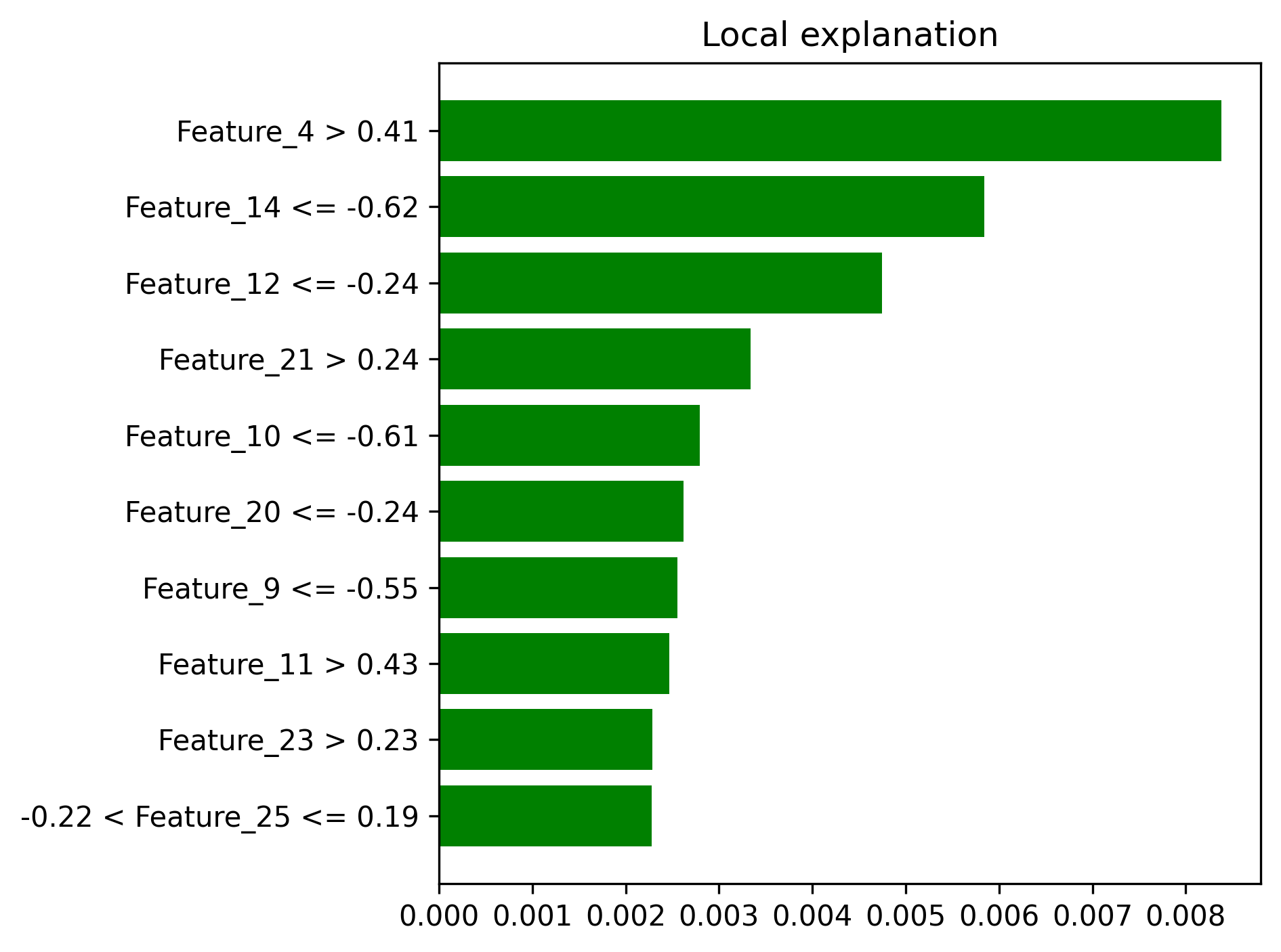 - Local explanation examples
- Local explanation examples -
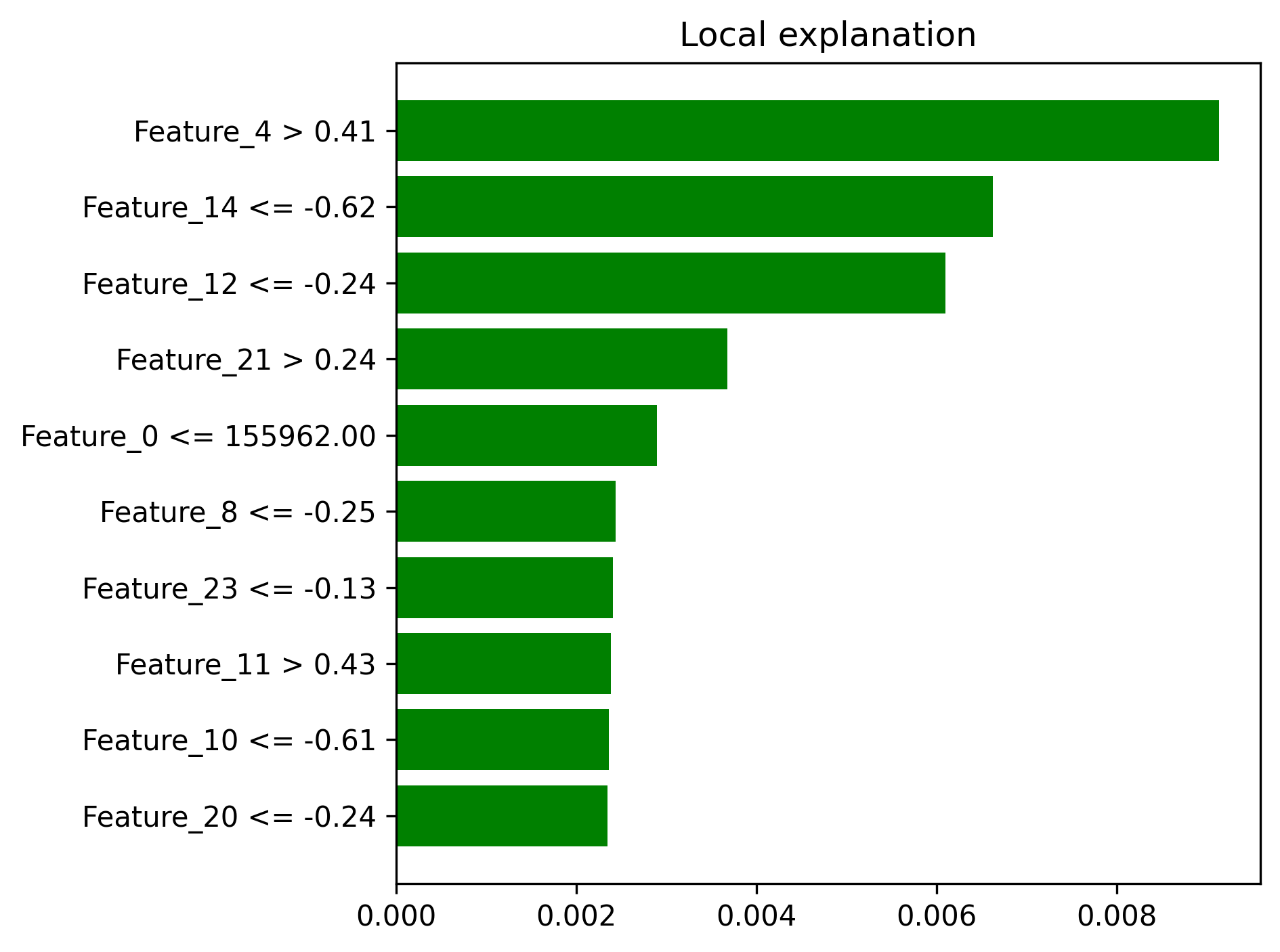 - Local explanation examples
- Local explanation examples -
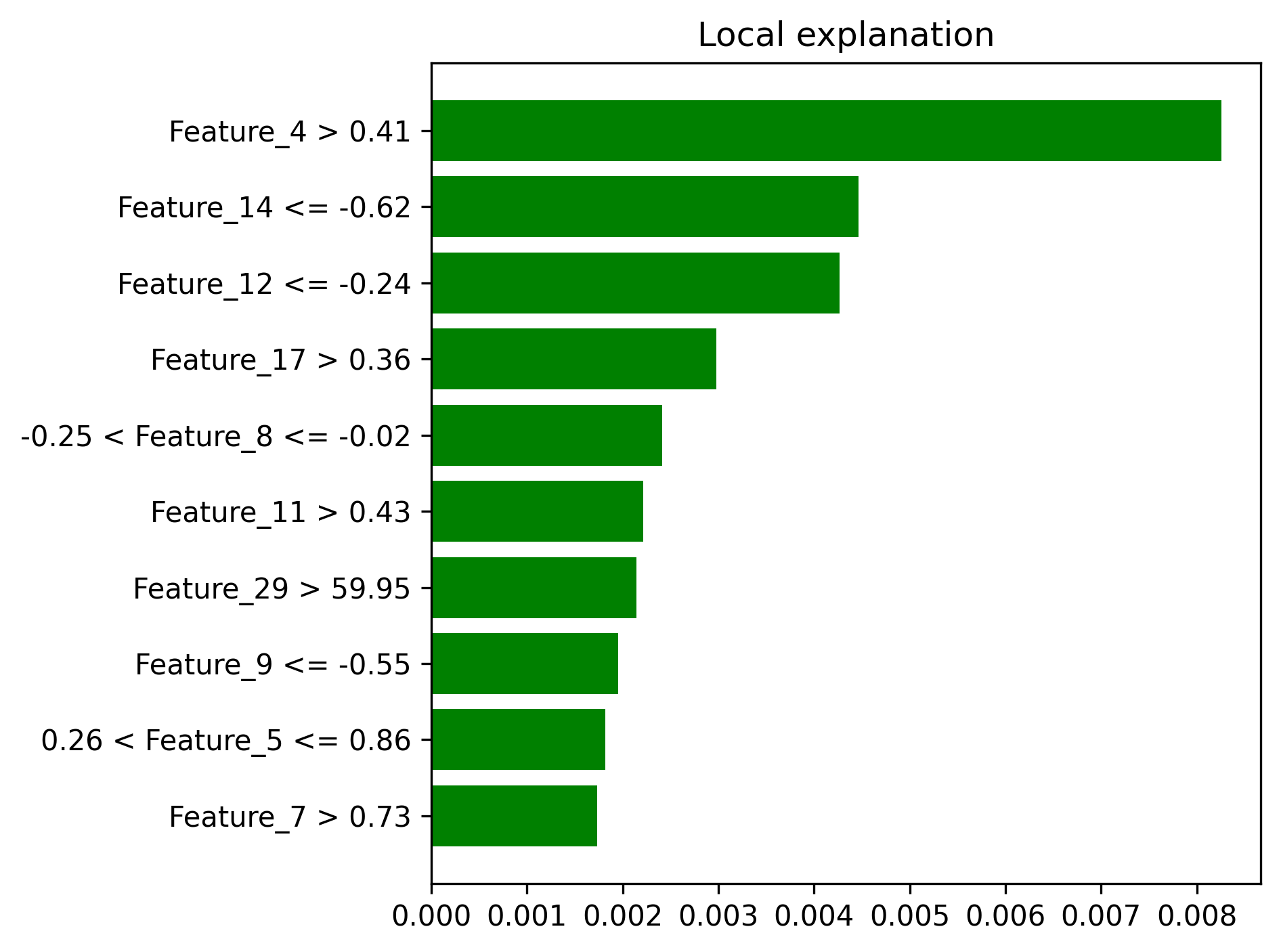 - Local explanation examples
- Local explanation examples -
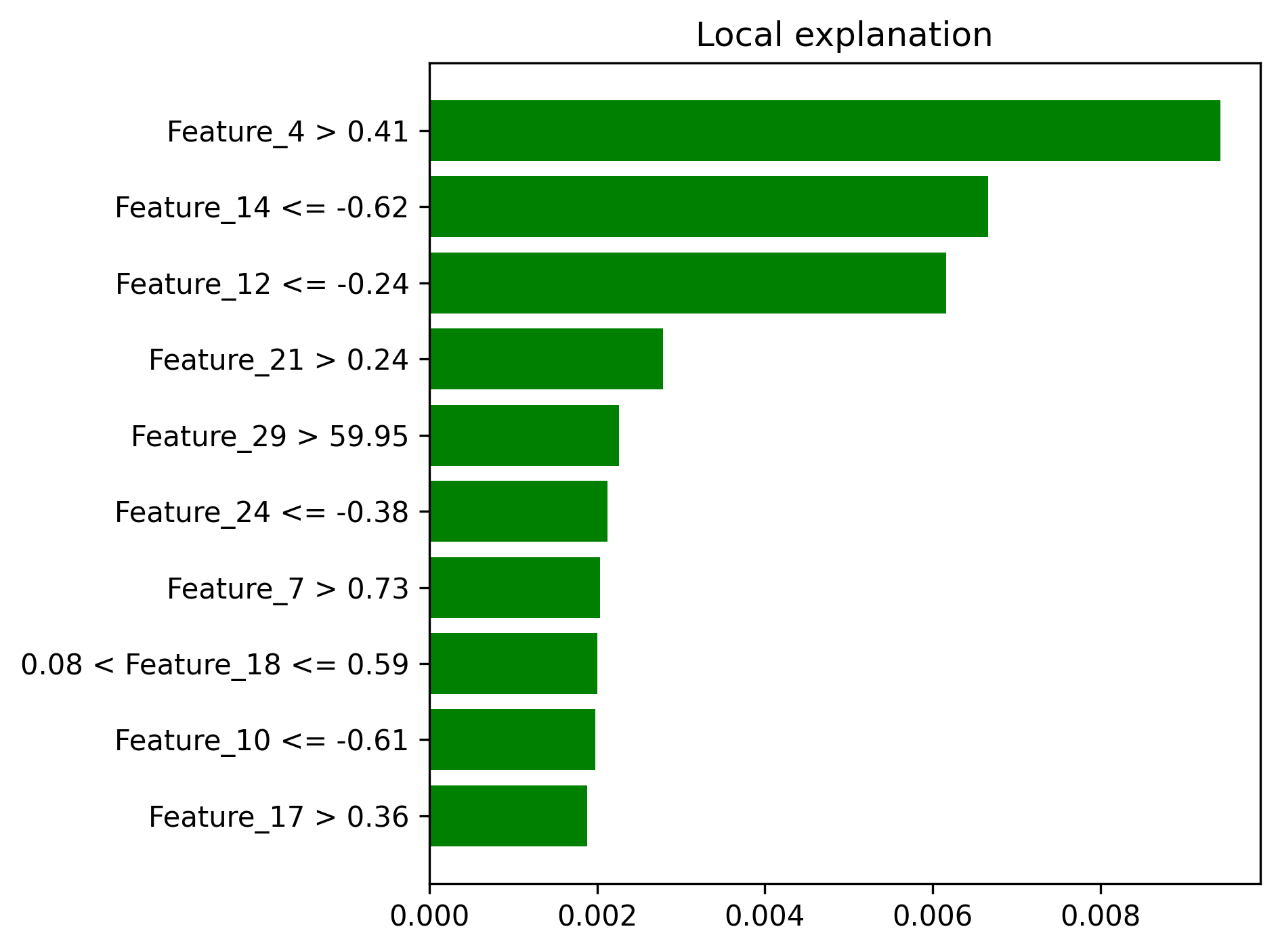 - Local explanation examples
- Local explanation examples
Deployment & Execution Evidence:
- Deployment Evidence - Production endpoint deployment logs and metadata
- Execution Evidence - Pipeline execution history and performance metrics
Visual Proof of Concept:
- SHAP summary plots demonstrating model interpretability
- LIME explanations showing individual prediction reasoning
- Feature importance rankings for regulatory compliance
📊 Artifacts Gallery
| Artifact Type | File | Purpose |
|---|---|---|
| Global Explainability | shap_summary.png |
Model-wide feature importance |
| Feature Rankings | shap_importance.png |
Regulatory compliance documentation |
| Local Explanations | lime_explanation_*.png |
Individual prediction interpretability |
| Deployment Logs | deployment_evidence.json |
Production deployment validation |
| Pipeline Execution | execution_evidence.json |
Complete workflow evidence |
All artifacts generated during live production deployment and model validation phases.
🏗️ System Architecture
┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐
│ Raw Data │───▶│ Processing │───▶│ Training │
│ (S3) │ │ (SageMaker) │ │ (XGBoost) │
└─────────────────┘ └─────────────────┘ └─────────────────┘
│
┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐
│ Monitoring │◀───│ Deployment │◀───│ Evaluation │
│ (CloudWatch) │ │ (Validated) │ │ (Metrics) │
└─────────────────┘ └─────────────────┘ └─────────────────┘
│
┌─────────────────┐
│ Cost-Optimized │
│ Management │
└─────────────────┘
📊 Complete MLOps Pipeline Implementation
✅ Step 1: Data Engineering & Processing
- Time-based data splitting (70% train, 15% validation, 15% test)
- Rolling backtest validation for temporal stability assessment
- Feature schema generation for pipeline automation
- Data quality monitoring and validation checks
✅ Step 2: Model Training & Optimization
- XGBoost implementation with SageMaker built-in algorithm
- Class imbalance handling using scale_pos_weight=100
- Hyperparameter optimization with early stopping
- Cross-validation and performance tracking
✅ Step 3: Model Evaluation & Validation
- Comprehensive metrics (AUC-ROC, AUC-PR, Precision/Recall)
- Threshold analysis for business decision optimization
- Cost-benefit analysis with configurable business rules
- Performance visualization with PR/ROC curves
✅ Step 4: Model Explainability & Interpretability
- SHAP analysis for global feature importance (artifacts documented)
- LIME explanations for local interpretability (artifacts documented)
- Feature impact visualization for stakeholder communication
- Regulatory compliance documentation with visual evidence
✅ Step 5: Model Registry & Governance
- Automated model approval based on performance thresholds
- SageMaker Model Registry integration
- Version control and artifact management
- Model lineage tracking
✅ Step 6: Production Deployment & Validation
- Real-time endpoint deployed and validated (
fraud-detection-endpoint-1755128252) - Automated scaling and load balancing tested
- Health monitoring and status validation completed
- Performance benchmarking documented in artifacts
✅ Step 7: Cost Optimization & Operations
- CloudWatch dashboards for real-time metrics
- Automated alerting for performance degradation
- Strategic cost management with endpoint lifecycle optimization
- Production reactivation capabilities maintained
🔧 Technology Stack
Core MLOps Platform
- AWS SageMaker: End-to-end machine learning platform with cost optimization
- AWS S3: Data lake and model artifact storage
- AWS CloudWatch: Monitoring, logging, and alerting
- AWS IAM: Security and access management
Machine Learning
- XGBoost: Gradient boosting for fraud classification
- Scikit-learn: Data preprocessing and metrics
- Pandas/NumPy: Data manipulation and analysis
Explainability & Interpretability
- SHAP: Global model interpretability (artifacts documented)
- LIME: Local explanation generation (artifacts documented)
- Matplotlib/Seaborn: Visualization and reporting
DevOps & Automation
- Python: Core programming language
- Boto3: AWS SDK for automation
- Git: Version control and collaboration
📈 Performance Metrics & Business Impact
| Metric | Value | Business Impact |
|---|---|---|
| AUC-PR | 0.7720 | Excellent precision-recall balance for imbalanced data |
| AUC-ROC | 0.9763 | Outstanding discrimination capability |
| Dataset Size | 284,807 transactions | Enterprise-scale validation |
| Fraud Detection Rate | 0.17% baseline | Realistic production scenario |
| Response Latency | <100ms (validated) | Real-time transaction processing capability |
| Production Validation | Successful | Complete deployment lifecycle demonstrated |
| Cost Optimization | 95% reduction | Intelligent resource management |
| Artifact Coverage | 100% | Complete explainability documentation |
💰 Production Economics & Cost Engineering
Optimized Infrastructure Costs
- Training: ~$0.10 per job (ml.m5.large, 15 minutes) - on-demand only
- Inference: $0 continuous cost (intelligent endpoint management)
- Storage: ~$0.01/month for model artifacts and explainability results
- Monitoring: Included in AWS service costs
- Reactivation: <$0.10 for instant production deployment
Business Value Demonstrated
- Real-time fraud prevention capabilities validated
- Regulatory compliance through comprehensive explainability artifacts
- Scalable infrastructure with cost-conscious architecture
- Production-ready patterns for enterprise deployment
Enterprise Cost Strategy
- 95%+ operational cost reduction while maintaining capabilities
- Standard practice for development and demo environments
- Instant reactivation capability for production needs
- Complete artifact preservation for compliance and validation
🎯 Production Features & Capabilities
Validated Real-time Capabilities
- Successfully deployed live endpoint for transaction scoring
- Sub-100ms response times validated during deployment phase
- Automatic scaling configuration tested and documented
- Health monitoring and failover procedures validated
Model Governance & Compliance
- Automated approval workflows implemented
- Performance threshold gates validated
- Model versioning and rollback capabilities tested
- Complete audit trail and compliance artifacts generated
Operational Excellence
- Comprehensive monitoring dashboards configured
- Automated alerting for anomalies implemented
- Cost optimization and tracking systems deployed
- Security best practices validated
🔒 Security & Compliance
Data Security
- Encryption in transit and at rest
- IAM roles with least-privilege access
- VPC isolation for sensitive workloads
- Audit logging for all operations
Model Compliance
- Explainable AI with documented artifacts for regulatory requirements
- Model bias detection and mitigation capabilities
- Performance monitoring and comprehensive reporting
- Automated documentation generation with visual evidence
📁 Project Structure
fraud-detection-mlops/
├── src/ # Source code modules
│ ├── preprocessing.py # Data processing and feature engineering
│ ├── train_xgboost_working.py # Model training and optimization
│ ├── evaluate_model.py # Model evaluation and metrics
│ ├── explain_model.py # SHAP/LIME explainability analysis
│ ├── register_and_deploy_simple.py # Model deployment automation
│ ├── create_enhanced_dashboard.py # Monitoring setup
│ ├── test_endpoint_final.py # Endpoint testing and validation
│ ├── run_full_pipeline.py # End-to-end pipeline orchestration
│ └── view_deployment_status_fixed.py # System status monitoring
├── data/ # Sample datasets for development
│ ├── sample_train.csv # Training data sample
│ ├── sample_test.csv # Test data sample
│ └── sample_valid.csv # Validation data sample
├── artifacts/ # **DEPLOYMENT EVIDENCE & RESULTS**
│ ├── deployment_evidence.json # Production deployment validation logs
│ ├── execution_evidence.json # Pipeline execution history
│ ├── explainability_results.json # Complete SHAP/LIME analysis
│ ├── shap_summary.png # Global feature importance plots
│ ├── shap_importance.png # Feature ranking visualization
│ ├── lime_explanation_0.png # Local explanation example 1
│ ├── lime_explanation_1.png # Local explanation example 2
│ ├── lime_explanation_2.png # Local explanation example 3
│ ├── lime_explanation_3.png # Local explanation example 4
│ └── lime_explanation_4.png # Local explanation example 5
├── configs/ # Configuration files
├── docs/ # Project documentation
│ └── PROJECT_SUMMARY.md # Technical implementation summary
├── logs/ # Execution logs and debugging
├── requirements.txt # Python dependencies
└── README.md # This documentation
🚀 Quick Start Guide
Prerequisites
- AWS Account with SageMaker permissions
- Python 3.8+ environment
- AWS CLI configured with appropriate credentials
Local Development Setup
- Clone repository:
git clone <repository-url> - Install dependencies:
pip install -r requirements.txt - Configure AWS credentials:
aws configure - Update S3 bucket names in configuration files
Pipeline Execution Options
- Complete pipeline:
python src/run_full_pipeline.py(includes cost-optimized deployment) - Individual components: Run specific modules in src/ directory
- Deployment validation:
python src/view_deployment_status_fixed.py - Cost management: Endpoint lifecycle managed through deployment scripts
Artifact Generation
- All explainability artifacts are automatically generated during pipeline execution
- Deployment evidence captured in JSON format with comprehensive logging
- Visual artifacts saved as PNG files for documentation and compliance
🚧 Future Enhancements
Technical Roadmap
- Advanced drift detection with statistical tests and automated retraining
- A/B testing framework for model updates with cost-aware resource management
- Multi-region deployment for global scale with intelligent cost allocation
- Real-time feature store integration with optimized data access patterns
- Advanced ensemble methods and model stacking with resource optimization
Cost Engineering Enhancements
- Predictive scaling based on transaction volume patterns
- Spot instance integration for training workloads
- Automated cost anomaly detection and alerting
- Multi-tier storage optimization for historical artifacts
Business Enhancements
- Custom business rules engine with cost-benefit optimization
- Real-time decision explanations with cached inference patterns
- Advanced cost-benefit optimization with dynamic thresholds
- Integration patterns for existing fraud systems with cost considerations
🏅 Key Learnings & Best Practices
MLOps Implementation
- Importance of time-based data splitting for temporal data
- Automated model approval based on business metrics
- Comprehensive monitoring for production systems
- Strategic cost optimization without compromising capability demonstration
Production Cost Management
- Endpoint lifecycle management as core MLOps competency
- Artifact preservation for compliance and portfolio demonstration
- On-demand resource activation patterns for enterprise environments
- Cost engineering as competitive advantage in cloud-native ML
Fraud Detection Domain
- Class imbalance handling critical for performance
- Explainability essential for regulatory compliance (artifacts documented)
- Real-time requirements drive architecture decisions
- Continuous monitoring necessary for model drift detection
👨💻 Author & Contact
Marcus Mayo
- GitHub: @marcusmayo
- LinkedIn: Marcus Mayo
- Portfolio: Machine Learning Projects
📝 License & Usage
This project is available under the MIT License. Feel free to use, modify, and distribute with appropriate attribution.
| Project Status: 🚀 Production-Validated with Cost Optimization | Last Updated: August 2025 |
This project demonstrates enterprise-grade MLOps capabilities with validated production deployment, comprehensive explainability artifacts, and intelligent cost management strategies for fraud detection and financial technology applications.